

Application Scenarios
Z Company's Sensitive Sentence Detection Algorithm Achieves Recall Rate of Over 97%
Project Background:
With the rapid development of internet technology, online content is experiencing an explosive growth. However, this surge has also led to some users posting illegal or inappropriate material on the internet, including violent, explicit, fraudulent, and harassing content. This not only harms others and gives rise to social conflicts but also poses a threat to the order and public safety of online communities. In order to protect users' legal rights, maintain the healthy development of online communities, and comply with government regulations, major internet companies need to conduct content moderation and implement more accurate, efficient, and automated review processes through AI technology. Z Company, a social media company, needs to utilize a sensitive sentence detection algorithm to monitor platform content and build a harmonious online environment.
Project Challenges:
Sensitive sentence detection is a text classification task that involves identifying sensitive information through machine learning models. It enables real-time monitoring and filtering of text content, and is widely applied in social media platforms, online forums and communities, financial and insurance industries, government departments, and sentiment analysis, among others. However, this project faces three major challenges:
1. Data Acquisition
Sensitive sentences come in various types and forms, requiring a large amount of sample data to cover all possible cases. However, sensitive sentences are usually very rare in reality, as online content has already undergone filtration. Therefore, acquiring sufficient and relevant data is costly and inefficient, resulting in a scarcity of effective data.
2. Semantic Analysis
Sensitive sentences encompass a wide range of semantic meanings, making it challenging to define accurate labeling rules. Human subjectivity can easily introduce errors into the labeling process. For example, the sentence "Trump built a wall in the southern part of the United States" is a sensitive sentence involving racial discrimination. However, it requires extensive historical, geographical, and cultural knowledge for humans to recognize its sensitivity. Models need precise labeling rules to make accurate predictions. Another example is the sentence "Someone shot someone." While this sentence involves violence, "The police shot and killed a criminal" is not considered a sensitive sentence. The rich semantic variations require models to have detailed explanations and instructions to achieve sensitive sentence recognition.
3. Model Iteration
The scarcity of data, the diversity of sensitive sentence types across different domains and cultures, make it difficult for algorithms to generalize and address overfitting issues. The results of sensitive sentence algorithms also have a certain degree of subjectivity and uncertainty, increasing the complexity and difficulty of algorithm iteration.
Solution:
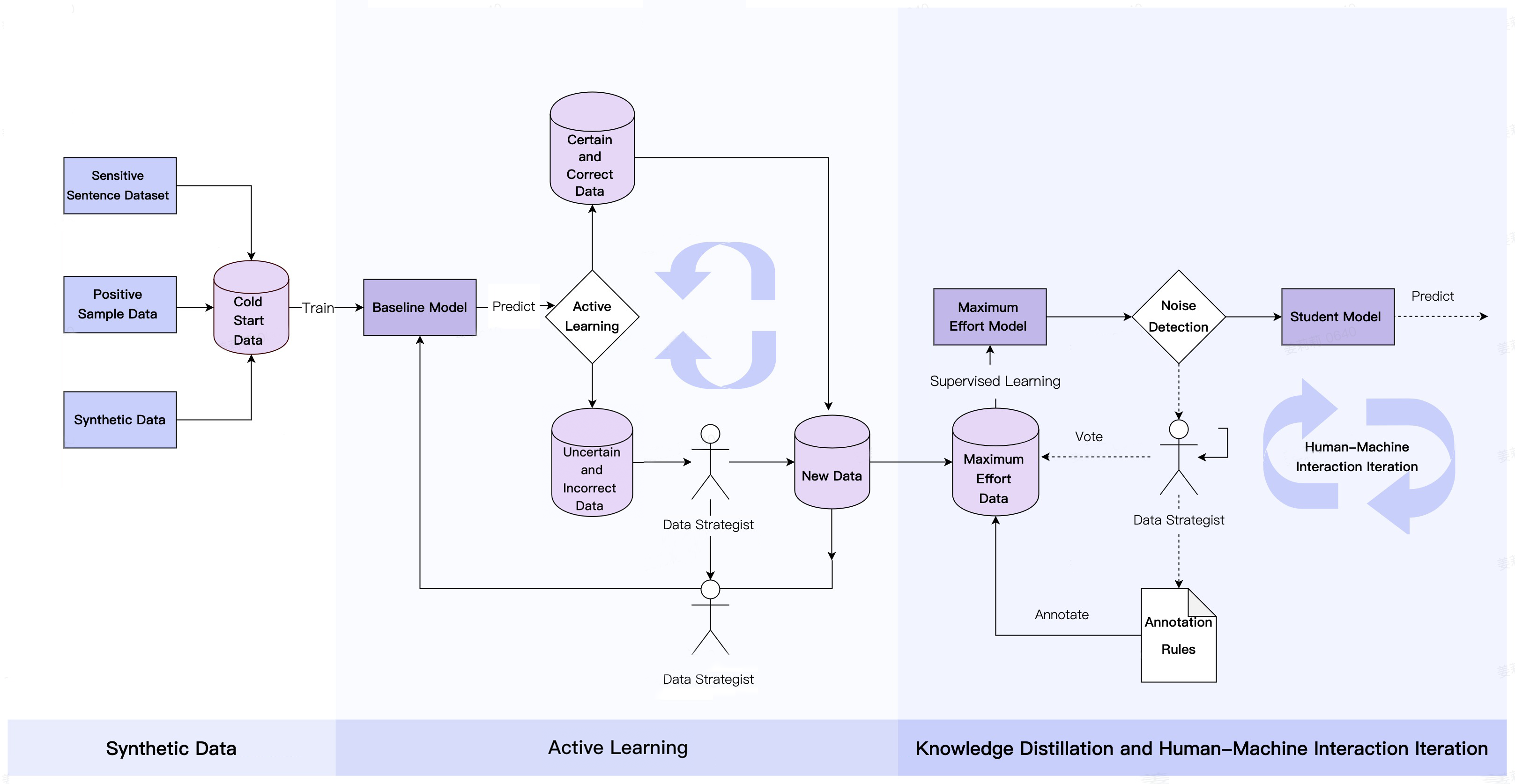
To address these challenges, we have developed a sophisticated combination of data strategies to maximize the recognition capabilities and accuracy of the algorithm, and as a result the quality of the data set, labeling rules, and model performance would be optimized. The specific strategies are as follows:
1. Synthetic Data
By using the GPT model, we can generate a large volume of high-quality sensitive sentence data from various angles, styles, and lengths to supplement the scarcity of real data. Synthetic data allows us to control the types, quantity, quality, and distribution, reducing dependence on the collection and processing of real data and thereby improving training efficiency.
2. Active Learning
Through effective data selection strategies, active learning enables us to achieve performance comparable to using a large amount of labeled data while using minimal labeled data, thereby reducing labeling costs and improving model effectiveness. The model actively selects samples that need to be labeled for iterative training, optimizing data quality and model performance.
3. Knowledge Distillation & Human-in-the-loop Iteration
Leveraging a teacher model, we train the final student model and optimize the dataset and labeling rules with human-machine interaction strategies. Through iterative processes, we continuously improve the model and data quality, enhancing the algorithm's accuracy and generalization abilities.
Effect:
Based on the aforementioned data strategies, our sensitive sentence detection algorithm demonstrates outstanding performance. It achieves a high level of accuracy, low false positive rates, and a recall rate of over 97%, surpassing the industry average of 80%-90% for recall rates. The algorithm has been successfully applied in practical projects, delivering excellent results. Additionally, our algorithm exhibits adaptability and high customization, allowing flexible adjustments and optimization to meet the needs of various industries and application scenarios. It effectively addresses diverse situations and challenges.



Algorithm Team Leader, Z Company
"The sensitive sentence detection algorithm provided by Stardust offers us an efficient and accurate solution. Their algorithm provides strong support in building a harmonious online environment."
More customer cases



Empower machines to speak and write, training more responsive OCR and ASR models
"Stardust has been able to meet our highly customized data needs effectively. With their extensive overseas resources, they provide comprehensive data services, including collection, annotation, QC, and delivery, offering a full-stack data solution."



R&D Supervisor, X Company



To Build a National-Level NLP/New Media Laboratory
"Stardust is our trusted partner in establishing the National Key Laboratory for Integrated Media. Their annotation system supported by algorithms and the team with strong news sense and political understanding ensures top-quality news annotations."



Technical Director, X News Agency



Equip autonomous vehicles with clearer and more sensitive vision.
"The Stardust platform can achieve API-based data validation and real-time monitoring of data quality. The Stardust team has extensive experience in data annotation in the autonomous driving field, enabling them to provide professional advice to us."



Perception System Leader, X Autonomous Vehicle Company
Explore More
Fill out the form to schedule a personalized demo with our team. Experience firsthand how our innovative solutions can meet your needs and drive success.
Copyright © 2025 StardustAI Inc. All rights reserved.