

Data-centric AI
解决“数据债”隐患的新范式
Data-centric AI强调数据在机器学习中的重要地位。一个完整的机器学习全生命周期数据管理系统,不仅决定了数据的质量和使用效率,还直接影响了模型效果的上限。
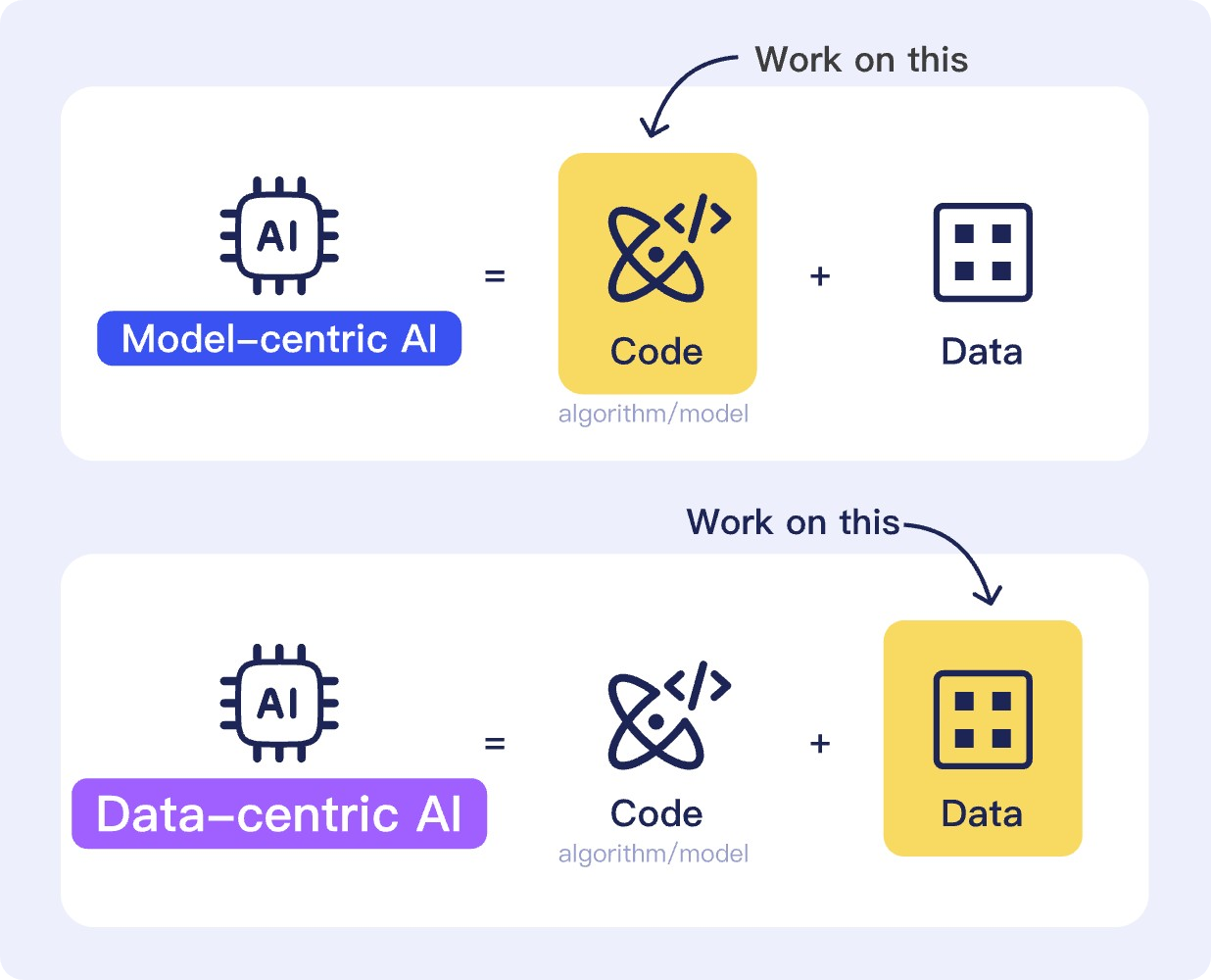
什么是数据债
类似于软件开发过程中的“技术债”,“数据债”是指在机器学习的各个环节中,由于低估了数据的重要性,在推进项目的过程中忽视了数据质量的把控,从而欠下的各种“债务”
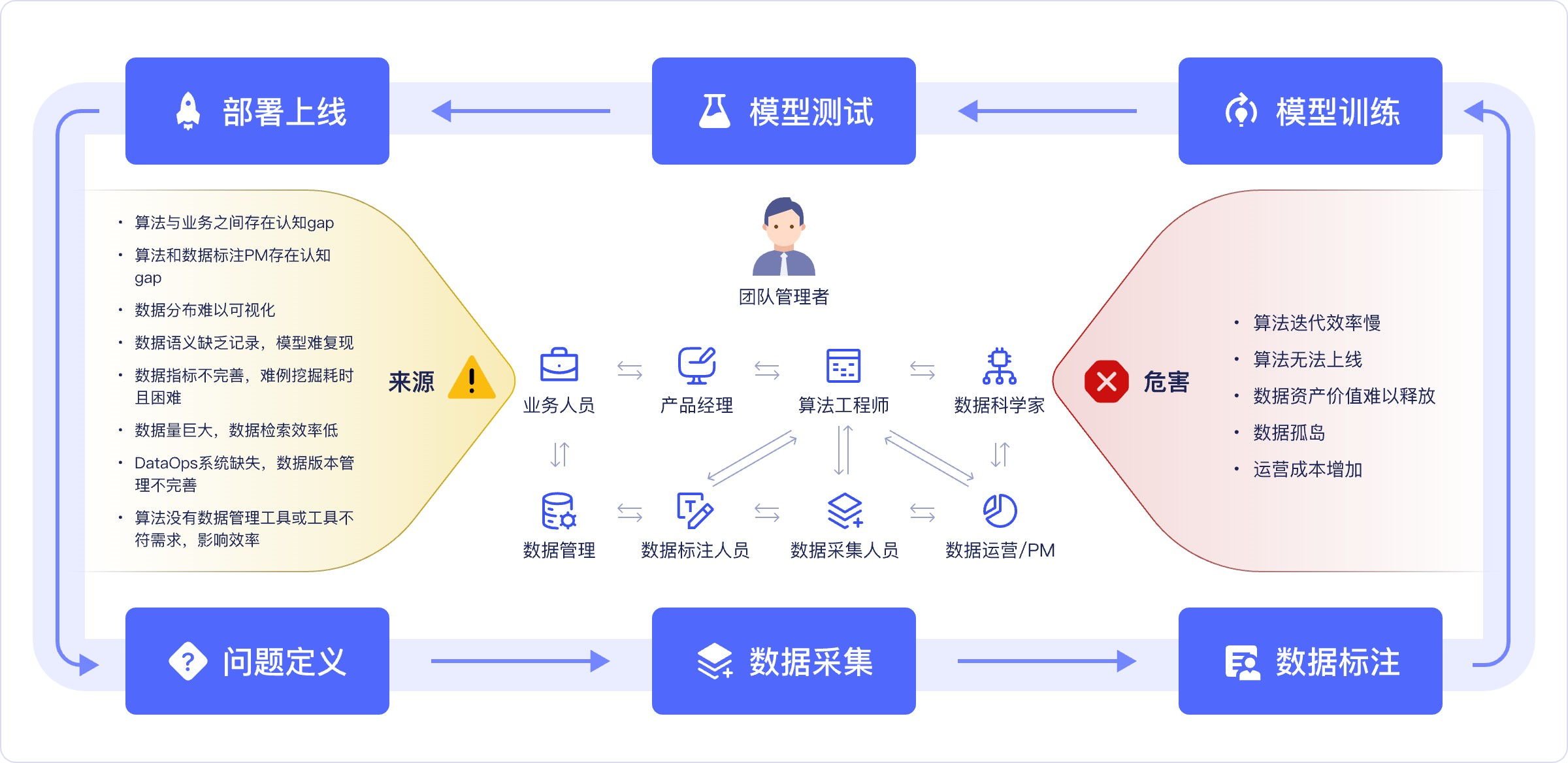
数据债的来源
低估数据的重要性,会在机器学习全生命周期中不断累计数据债
数据债=模型差=业务问题无法解决
“为何做”与“如何做”
算法工程师与数据标注PM认知之间的gap
算法工程师强调“数据>算法>创新”的思路,重视数据的价值和质量。他们会准确评估数据的价值,定义数据标注的边界,并对数据进行详细记录和分析。但数据标注工作通常是由数据运营/数据项目经理作为“中间人”去找供应商或者标注团队来完成。算法工程师和数据标注项目经理之间的认知差异,便可能导致标注需求不明确、标注规则不统一等问题,进而造成重复标注、多次返修、无效标注等“数据债”。

“理想”与“现实”
算法训练与业务应用之间的gap
算法研发还面临另一个挑战——如何在真实的业务场景落地并产生业务价值?能解决应用问题的算法=好的模型=好的数据,反之亦然。但即使算法训练效果再好,一旦面对真实而复杂多变的环境,其准确率也可能显著下降。所以,算法工程师需要耗费大量的时间和精力仔细研究数据,找出数据异常之处,了解数据规律,反复编排流程,比较版本差异,才能最终达到提高模型的泛化性的效果。而在研究、分析、使用、迭代数据的过程中,便可能产生大量的”数据债“。
“规则”与“实操”
文档不统一和跨组织执行之间的gap
理想情况下,算法工程师需要对所标注的数据进行预处理,目的是为了节省标注时间和成本、降低标注难度。然而事实确是为了尽快完成产品的开发,算法工程师往往会直接准备好数据交给标注员,甚至放弃对部分数据边界的分析,给出的标注规则和文档也不够清晰。没有统一的规则和清晰的指导,数据经过能力参差不齐的标注团队之后,就会形成大量的数据债。
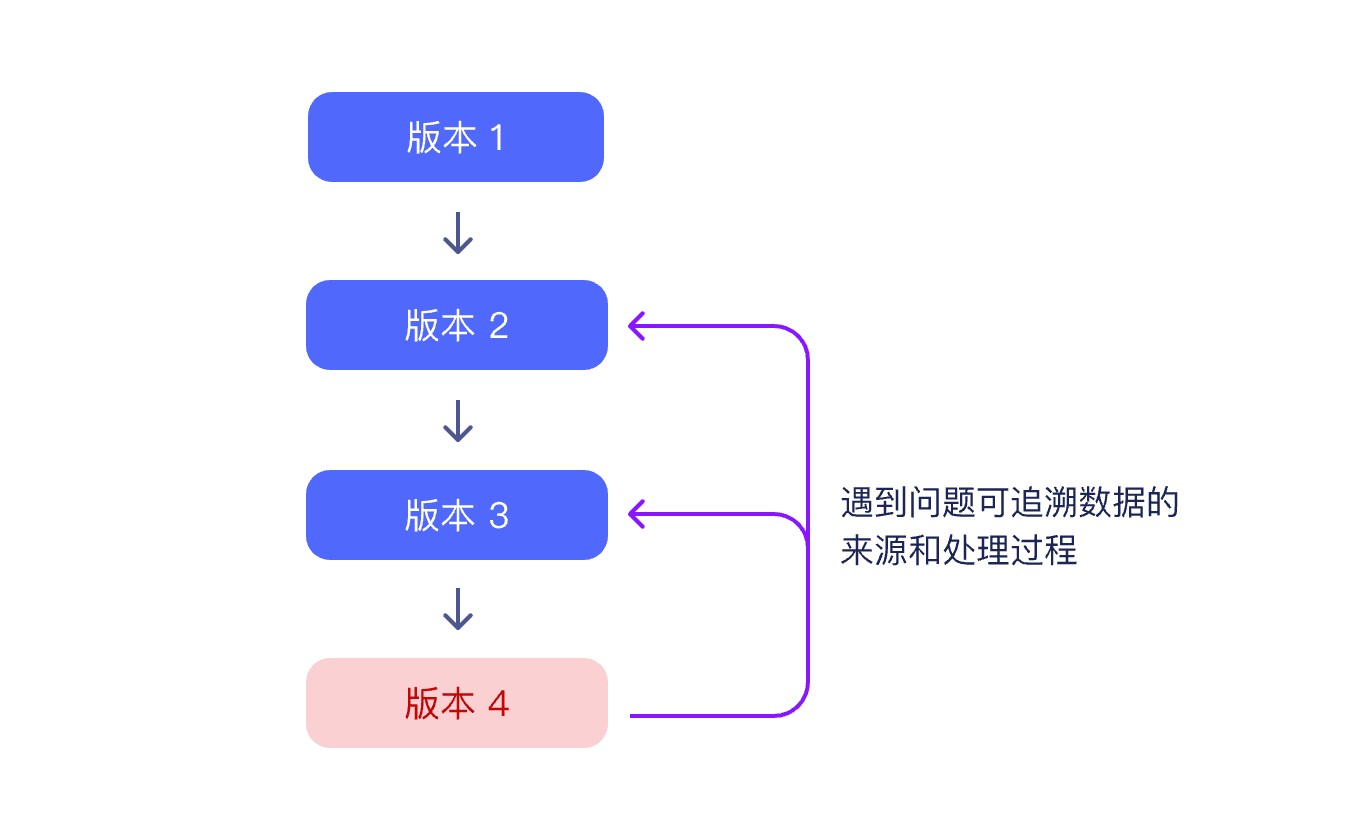
“对症”与“下药”
算法需求与数据工具链缺失的gap
在实际的算法训练和迭代过程中,算法工程师通常在发现模型效果不佳或遇到错误时才开始严格管理数据,这种应急处理的方式看似成本小,实际上却是一颗定时炸弹。如果数据版本没有得到妥善管理,会导致在模型效果出现问题时无法准确追溯到数据的来源和处理过程,无法还原问题点。然而,目前市面上大部分处理数据的工具都不具备流程追溯的功能。

“高价值”与“高浪费”
数据资产与数据管理之间的gap
• 数据价值无法释放:很多企业的数据存在无管理、无利用、无价值的“三无”情况。数据的价值被白白浪费,数据处理效率缓慢,企业无法把握日益激烈的市场竞争和不断变换的市场环境,竞争力变弱。
• 数据冗余重复:由于缺乏统一的数据管理和共享机制,企业各个部门之间存在“数据孤岛”现象。这不仅会导致数据无法被充分利用,还会浪费大量的资源,给企业带来不必要的额外成本。
有了 MorningStar,再无数据债烦恼
星尘数据打造的一站式 AI 数据管理平台 MorningStar,基于 DataOps 的思想和理念,针对开发过程中存在的各种数据债问题,帮助企业实现机器学习闭环全链路打通,全力打造专注高效迭代的算法生产环境
你的模型,你说了算
通过MorningStar实现数据的全生命周期管理,强化数据版本控制,快捷生成数据切片,一键追溯数据源头,数据即安全又可控。MorningStar的自动化工作流能确保你的数据在每个阶段都能得到妥善的管理和最优化处理。
用专属你的最优质的数据,训练出你最理想的模型。
你的模型,千变万化
MorningStar 自带颗粒度可视化、指标计算、数据分布探索、跨模态数据检索等丰富的数据挖掘工具,助力企业发现数据的全面价值。
通过人工监督、语义检索、特征生成和数据增强等手段,提高算法效果。
在无限可能的数据中,诞生出千变万化的模型。

你的模型,遥遥领先
MorningStar 能够确保企业模型训练的全过程可追踪可迭代。通过一系列数据追溯、模型调试、分析报告工具,助力企业实现和维护高质量、可再生成的 AI 模型。
在垂直领域茁壮成长,你的模型,遥遥领先。
了解更多
请填写您的企业邮箱,可获取更详细的介绍资料、个性化购买咨询服务

© 2025 北京星尘纪元智能科技有限公司 保留所有权