

客户案例
构建和谐网络环境,Z公司敏感句检测召回率达97%以上!
项目背景
随着互联网技术的迅猛发展,网络上的内容呈现爆炸式增长的趋势。然而,一些用户在互联网上发布违法、违规的内容,如暴力、色情、欺诈、骚扰等,这不仅会伤害他人、引发社会矛盾,甚至犯罪行为,还对互联网社区的秩序和公共安全构成威胁。为了保障用户的合法权益,维护互联网社区的健康发展,满足政府法规的要求,各大互联网公司需要进行内容审核,并通过AI技术实现更准确、高效、自动化的审核流程。Z 公司是一家社交媒体公司,需要利用敏感句检测算法对平台内容进行监控,构建和谐网络环境。
项目难点
敏感句检测需要通过机器学习模型识别敏感信息,实现对文本内容的实时监控和过滤,被广泛应用于社交媒体、在线论坛和社区、金融保险、政府部门、舆情分析等领域。然而,该项目面临以下三大难点:
1、获取数据难
敏感句的种类和形式多种多样,要覆盖所有情况需要大量样本数据。但现实中敏感句通常非常少见,网络上的内容已经进行了过滤,因此获取有效数据的成本极高、效率低下。
2、语义分析难
敏感句涵盖的语义范围广泛,标注规则制定难度高,容易产生主观误差。模型需要精细的标注规则才能准确预测敏感句,而人类需要丰富的知识才能判断敏感句的涵义。
3、模型迭代难
数据量少、敏感句类型多样以及不同领域、不同文化的差异使得算法难以进行泛化,难以解决过拟合等问题。敏感句算法的结果也具有一定程度的主观性和不确定性,增加了算法迭代的复杂性和困难性。
解决方案
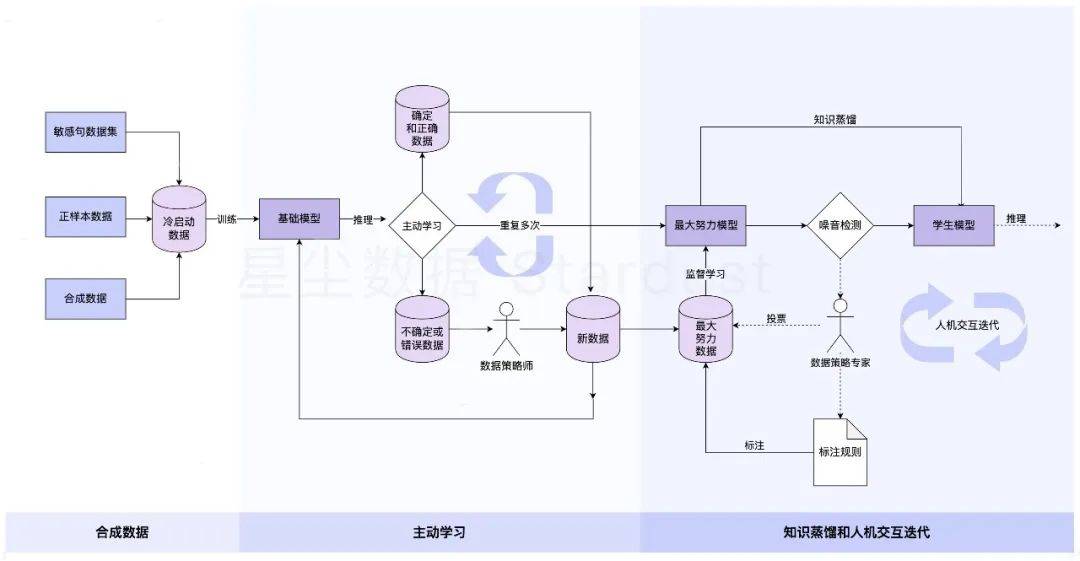
为了解决上述难题,我们采用了一套精巧的数据策略组合拳,旨在最大程度提高算法的识别能力和准确性,优化数据集、标注规则和模型效果。具体策略如下:
1、合成数据(Synthetic Data)
通过使用GPT模型生成大量不同角度、风格和长度的高质量敏感句语料,以补充真实数据的不足。合成数据可控制类型、数量、质量和分布,减少对真实数据采集和处理的依赖,提高训练效率。
2、主动学习(Active Learning)
通过有效的数据选择策略,利用少量标注数据获得与大量标注数据相当的性能,节省标注成本,提高模型效果。模型主动选择需要标注的样本进行迭代训练,优化数据质量和模型性能。
3、知识蒸馏(Knowledge Distillation)+人机交互迭代(Human in the loop)
借助老师模型进行知识蒸馏,训练最终的学生模型,并结合人机交互策略,优化数据集和标注规则。通过迭代的方式,不断改进模型和数据质量,提高算法的准确性和泛化能力。
效果
基于以上数据策略,我们的敏感句检测算法表现优秀,准确率高,误报率低,召回率达到97%以上,远超行业一般召回率80%-90%。该算法已成功应用于实际项目,并取得了良好的效果。此外,该算法具有自适应性和高可定制性,可以根据不同行业和应用场景的需求进行灵活调整和优化,应对各种情况和挑战。



某社交媒体公司算法团队负责人
"星尘数据的敏感句检测算法为我们提供了一种高效、准确的解决方案。通过 API 接入,他们的算法为我们维护互联网社区秩序,构建和谐网络环境提供了有力的支持。"
更多客户案例



让机器能说会写,训练更灵敏的OCR模型和ASR模型
"在过往合作中,星尘能够支持我们定制化程度超高的数据需求,并依靠其丰富的海外资源,综合采集、标注、质检、输出等环节,构建专业的一站式数据服务解决方案。"



某大型AI科技公司研发主管



目标:打造国家级NLP/新媒体实验室
"星尘是我们在建设开拓融媒体国家重点实验室道路上的可靠合作伙伴,他们的系统具备高实用性、实践性,在标注层面用算法辅助大幅度提高效率;项目人员的新闻敏感度和政治素养使得他们高质量地完成新闻稿件标注工作。"



某国家权威国家通讯社技术主管



H公司2D3D融合标注 多传感器融合让感知更精准
"星尘的平台可以实现API化的数据验收、数据质量实时监测,输出高效、高质、精准且安全的数据;并且星尘团队依靠在无人车领域的丰富标注经验可以给到我们专业建议,这一点是难能可贵的。"



某无人车科技公司感知系统总监
了解更多
请填写您的企业邮箱,可获取更详细的介绍资料、个性化购买咨询服务

© 2025 北京星尘纪元智能科技有限公司 保留所有权